Arama Motoru İndekslemesi ve Sayfa Blokaj Yöntemleri
İndeksleme nedir?
İndeksleme, site sayfalarının analiz edilmesi sürecidir (bu normalde arama motorları tarafından yapılır) ve ardından taramadan sonra bunları arama motoru indekslerine eklemektir. Bu indeks (veritabanı) daha sonra arama sonuçlarını oluşturmak için kullanılır ve ayrıca arama sonuçları içindeki sayfaların sıralaması için kullanılır (algoritmalar sayfaları sorgu niyeti tatmini ve başarılı SEO temelinde daha fazla analiz ettikten sonra). İndeksleme, bir tarayıcı/arama motoru robotu tarafından gerçekleştirilir.
Arama motoru indekslerinden bilgileri hariç tutma yeteneğine neden ihtiyacımız var?
Genel bir kural olarak, arama sonuçlarında görüntülenmemesi gereken bilgiler, “noindex” etiketi kullanılarak veya robots.txt dosyası içinde sitenin belirli bölümlerinin/sayfalarının taranmasını engelleyerek arama motoru indekslerinden engellenebilir.
Arama motorlarından normalde engellenen sayfalar teknik, özel mülkiyetli ve gizli niteliktedir ve arama sonuçlarına yerleştirilmeye uygun görülmez.
Bir ticari site içindeki örnekler; kullanıcıların hesaplarına, alışveriş sepetlerine, ürün karşılaştırmalarına, yinelenen sayfalara, site içindeki arama sonuçlarına vb. işaret eden bağlantılar olabilir!
Bu sayfalar müşteriler için değerlidir ve sitenin işlevselliği için gereklidir, ancak arama motoru indeksleri için yararlı değildir.
Sayfaları arama motorları tarafından indekslenmekten engellemenin yolları
Sayfaların indekslenmesini önlemenin birçok yolu vardır:
-
Robots.txt dosyası kullanma.
Robots.txt, arama motorlarına hangi sayfaları indeksleyebileceğini ve hangi sayfaları indeksleyemeyeceğini söyleyen bir metin dosyasıdır.
Robots.txt içinde bir sayfayı indekslenmekten engellemek için Disallow yönergesini kullanmanız gerekir.
Katalog sayfalarının indekslenmesine izin veren ancak sepetin indekslenmesine izin vermeyen bir robots.txt dosyası örneği:
# Sitenin kök dizininde bulunması gereken robots.txt dosyasının içeriği # '/catalog' ile başlayan sayfalar ve dosyaların indekslenmesine izin ver Allow: /catalog # '/cart' ile başlayan sayfalar ve dosyaların indekslenmesini engelle Disallow: /cart
-
<meta> robots etiketi ile noindex özniteliği kullanma.
Bu öznitelik kullanarak bir sayfayı engellemek için, sayfanın
<head>bölümüne aşağıdaki satırları eklemeniz gerekir:Tüm sayfayı indekslemeden engellemek için sayfanın
<head>bloğuna aşağıdaki satırı yerleştirmelisiniz:<meta name="robots" content="noindex">
-
Bağlantıları nofollow yaparak, bağlandıkları sayfayı indekslememelerini sağlamak.
Bunu yapmanın iki yolu vardır:
-
Tarayıcının bir bağlantıyı takip etmesini bağlantı bazında engelleme:
<a href="/page" rel="nofollow"> bağlantı metni </a>
Unutmayın ki bu yöntem, sayfaya giden her bağlantıda “nofollow” özniteliği varsa çalışacaktır. Eğer bir bağlantı bu özniteliği eksikse, arama motoru tarayıcısı onu takip edecek ve sayfa yine de indekslenecektir.
-
Sayfanın kendisindeki herhangi bir bağlantıyı takip etmeyi engelleyerek tarayıcının sayfa üzerindeki bağlantıları takip etmesini engelleme:
Sayfanın
<head>bloğuna aşağıdaki satırı ekleyerek, tarayıcı sayfayı takip etmekten engellenecek ve bu nedenle sayfa içindeki bağlantılar indekslenmeyecektir.<meta name="robots" content="nofollow" />
-
-
Ayrıca, HTML sayfasının başlığında belirli bir arama motoru tarafından sayfayı taranmaktan engelleyebilirsiniz, örneğin:
Bu satırı sayfanın
<head>bloğuna yerleştirebilirsiniz; bu, sayfayı Google tarafından indekslenmekten engelleyecektir (çünkü onların tarayıcısını tamamen engellediniz):<meta name="googlebot" content="noindex">
Ayrıca, belirli bir sayfayı “noindex” olarak ayarlamayı seçebilir ve Google'ın sayfadaki bağlantıları takip etmesine izin verebilirsiniz, ardından “noindex” sayfasından bağlanan sayfaları indeksleyebilirsiniz:
<meta name="googlebot" content="noindex, follow">
-
Kanonical sayfa.
Rel=canonical özniteliği, arama motoruna sayfanın canonical sayfa (en yetkili olan) olduğunu belirtmek için kullanılır. Bu, tarayıcıya bu sayfanın indekslenmesi tercih edilen sayfa olduğunu ve sitedeki bu içeriğin en yetkili örneği olduğunu gösterir.
Kanonical sayfaları belirtmek, aynı içeriğe sahip sayfaların indekslenmesini önlemek için gereklidir, bu da SERP'deki sayfa sıralamasını zarar verebilir.
Bu özniteliği, aynı içeriğe sahip ancak farklı cihazlar için farklı URL'lere sahip birden fazla sayfanız olduğunda kullanırsınız:
https://example.com/news/https://m.example.com/news/https://amp.example.com/news/
Veya sayfada birkaç 'sıralama' seçeneği mevcut olduğunda, sayfa URL'sini değiştirecek ancak aynı içeriği gösterecek:
https://example.com/catalog/https://example.com/catalog?sort=datehttps://example.com/catalog?sort=cost
Veya bağlantı, URL içinde verilen ürünün farklı boyutlarını belirtirse:
https://example.com/catalog/shirthttps://example.com/catalog/shirt?size=XLhttps://example.com/catalog/shirt38
Rel=canonical özniteliği aşağıdaki şekilde uygulanır:
<link rel=canonical href="https://example.com/catalog/shirt" />
Not: bu özniteliği sayfanın
<head>bloğuna yerleştirmelisinizAyrıca, istenen canonical sayfayı HTTP isteğinin başlığına girmek mümkündür.
Ancak dikkatli olun çünkü tarayıcınızın özel eklentilerini kullanmadan, bu özniteliğin doğru şekilde ayarlanıp ayarlanmadığını belirleyemezsiniz, çünkü çoğu tarayıcı HTTP başlıklarını kullanıcılarına göstermez.
HTTP / 1.1 200 OK Link: <https://example.com/catalog/shirt>; rel=canonical
Kanonical sayfalar hakkında daha fazla bilgiyi Google belgelerinde okuyabilirsiniz.
-
Belirli bir URL için "X-Robots-Tag" HTTP isteği başlığı kullanma:
HTTP / 1.1 200 OK X-Robots-Tag: google: noindex
Dikkatli olun çünkü tarayıcınızın özel eklentilerini kullanmadan, bu özniteliğin doğru şekilde ayarlanıp ayarlanmadığını belirleyemezsiniz, çünkü çoğu tarayıcı HTTP başlıklarını kullanıcılarına göstermez.
Sitemde indekslenmekten engellenen sayfaları nasıl bulurum?
Bu bilgiyi Labrika kontrol panelinizin "SEO denetimi" - "İndeksten engellenen sayfalar" bölümünde görüntüleyebilirsiniz.
Rapor sayfasında, indekslenmekten engellenen iniş sayfalarını görmek için sonuçları filtreleyebilirsiniz. Bunu yapmak için “kritik hata” düğmesine tıklamanız gerekir.
Tipik olarak, bir arama motoru tarayıcısı sitenizi ziyaret ettiğinde, iç bağlantılar aracılığıyla bulduğu tüm sayfaları tarayacak ve ardından buna göre indeksleyecektir.
Bu raporun amacı, indekslenmekten engellenen sayfaları göstermektir. Bunlar genellikle ilk 50 arama sonucunda anahtar kelime içermeyen sayfalar olup, arama motorlarından sizin tarafınızdan kasıtlı olarak engellenmiş olabilir.
Labrika’nın “İndeksten Engellenen Sayfalar” raporu
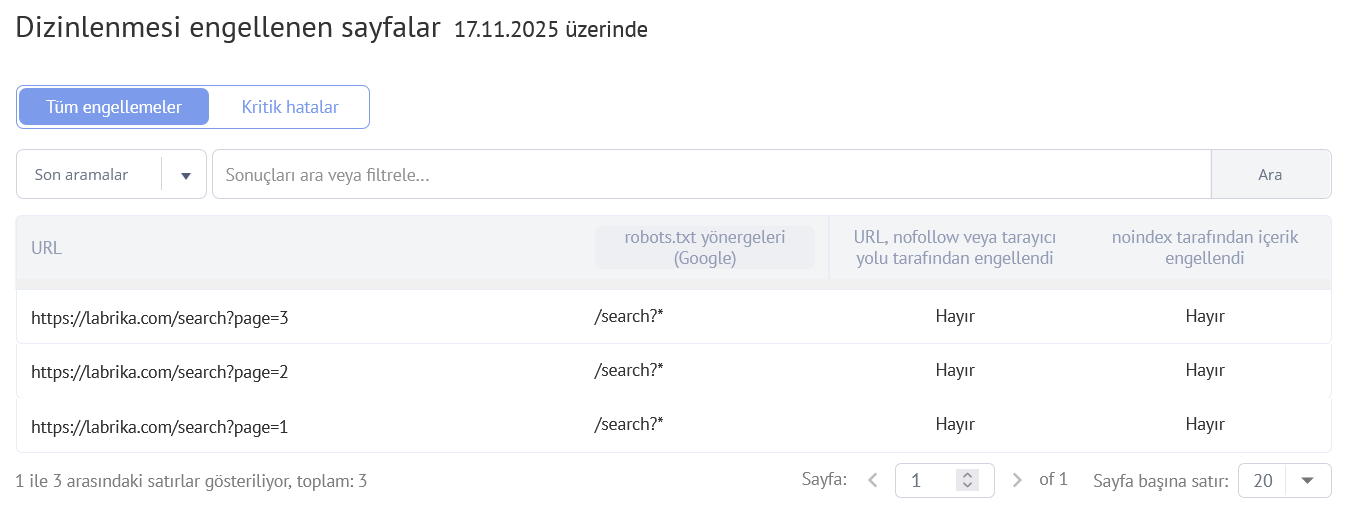
- Şu anda indekslenmekten engellenen sayfaların URL'si.
- Bu sayfa için indekslemeyi engelleyen robots.txt içindeki yönerge (eğer sayfa Google tarafından bu yöntemle indekslenmekten engellenmişse).
- Bu sayfanın nofollow özniteliği ile engellenip engellenmediği.
Bu rapor içinde bulunan bir sayfayı noindex olmaktan nasıl durdururum?
Birçok modern içerik yönetim sistemi (CMS) içinde robots.txt dosyasını, rel= canonical, "robots" meta etiketini, “noindex” ve “nofollow” özniteliklerini değiştirebilirsiniz. Bu nedenle, bu rapor içinde bulunan bir sayfayı tekrar indekslenebilir hale getirmek için, bu sayfayı indekslenemez hale getiren öznitelik/etiketi kaldırmanız yeterlidir. Bunu yapmanıza izin veren birçok basit eklenti vardır. Kendiniz değiştiremiyorsanız, bir geliştiriciye dış kaynak yapmak nispeten basit bir görev olacaktır.