Robots.txt Dosyası Nedir ve SEO İçin Neden Gerekli?
Robots.txt, site sayfalarının dizinlenmesine ilişkin talimatlar (yönergeler) içeren bir metin dosyasıdır. Bu dosya kullanılarak, arama robotlarına bir web kaynağında hangi sayfaların veya bölümlerin taranması ve arama motoru veritabanına (dizin) girilmesi gerektiğini ve hangilerinin taranmaması gerektiğini söyleyebilirsiniz.
Robots.txt dosyası sitenin kökünde bulunur ve domain.com/robots.txt adresinden erişilebilir.
SEO için robots.txt neden gerekli?
Bu dosya, arama motorlarına sitenin arama motorundaki sıralamasının etkinliğini doğrudan etkileyen temel talimatlar verir. Robots.txt kullanarak şunları yapabilirsiniz:
- Kullanıcılar için gereksiz sayfaların (iç arama sonuçları, teknik sayfalar vb.) arama motoru tarayıcıları tarafından taranmasını önleyin.
- Web sitesinin bölümlerinin gizliliğini koruyun (örneğin, CMS'deki sistem bilgilerine erişimi engelleyebilirsiniz);
- Sunucu aşırı yüklenmesini önleyin;
- Tarama bütçenizi değerli sayfaları taramak için etkili bir şekilde harcayın.
Öte yandan, robots.txt hatalar içeriyorsa, arama motorları siteyi yanlış dizinler ve arama sonuçları yanlış bilgiler içerir.
Ayrıca, sitenizin arama motorlarındaki sıralamaları için gerekli olan yararlı sayfaların dizinlenmesini yanlışlıkla engelleyebilirsiniz.
Aşağıda, Google'dan robots.txt dosyasının nasıl kullanılacağına ilişkin talimatlara bağlantılar bulunmaktadır.
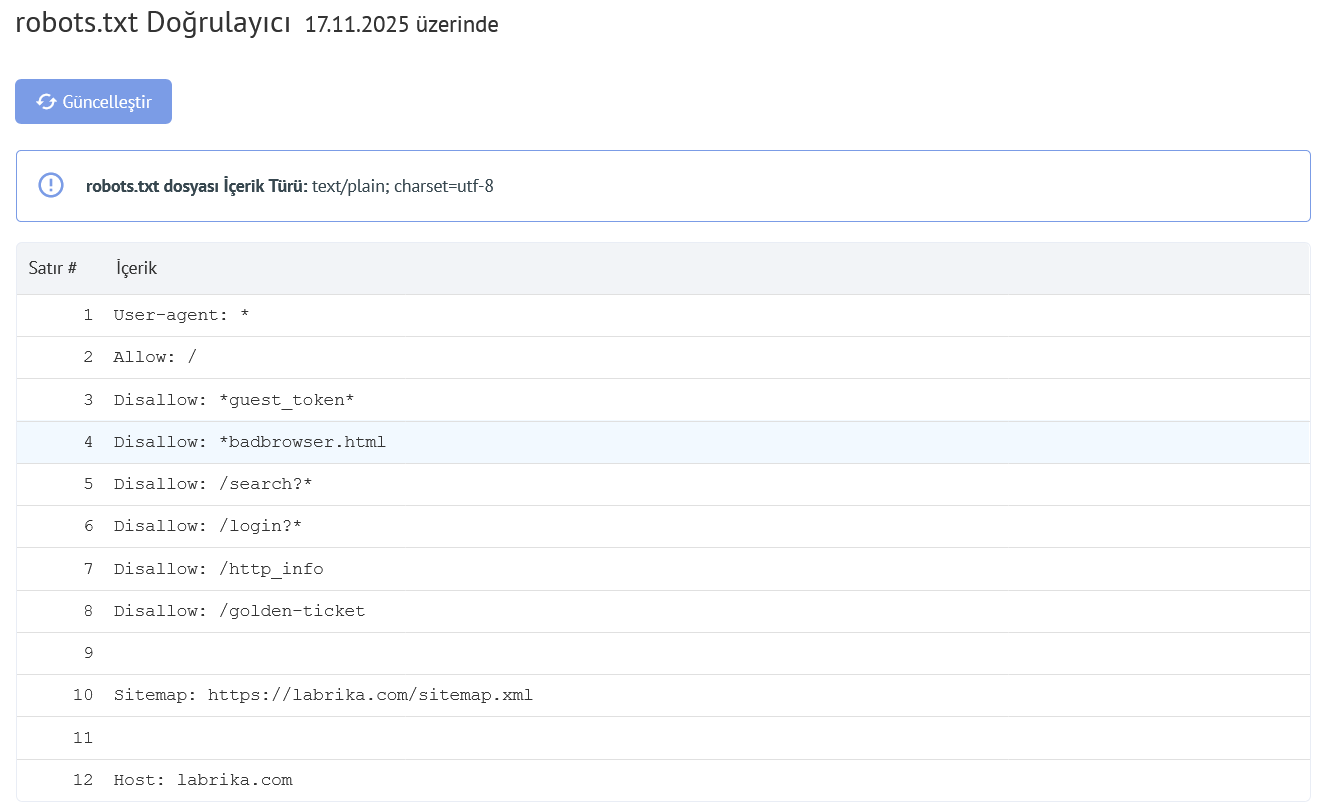
Labrika'da "Robots.txt Hataları" raporunun içeriği
Bu, "robots.txt hataları" raporunda bulacaklarınız:
- "Yenile" düğmesi - üzerine tıkladığınızda, robots.txt dosyasındaki hatalar hakkındaki veriler yenilenir.
- Robots.txt dosyasındaki içerik.
- Bir hata bulunursa, Labrika hata açıklamasını verir.
Labrika'nın tespit ettiği robots.txt hataları
Araç aşağıdaki hata türlerini bulur:
Yönerge, kuraldan ":" sembolü ile ayrılmalıdır
Robots.txt dosyanızdaki her geçerli satır, alan adı, iki nokta üst üste ve değer içermelidir. Boşluklar isteğe bağlıdır ancak okunabilirlik için önerilir. Hash sembolü "#" yorum eklemek için kullanılır ve bundan önce yer alır. Arama motoru robotu, "#" sembolünden satırın sonuna kadar olan tüm metni yok sayar.
Standart format:
<field>:<value><#optional-comment>
Bir hata örneği:
User-agent Googlebot
Eksik ":" karakteri.
Doğru seçenek:
User-agent: Googlebot
Boş yönerge ve boş kural
User-agent yönergesinde boş bir dize kullanmak yasaktır.
Bu, daha sonraki dizinleme kurallarının hangi tür arama robotu için yazıldığını belirten birincil yönergedir.
Bir hata örneği:
User-agent:
User-agent belirtilmemiş.
Doğru seçenek:
User-agent: botun adı
Örneğin:
User-agent: Googlebot veya User-agent: *
Her kural en az bir "Allow" veya "Disallow" yönergesi içermelidir. Disallow, bir bölüm veya sayfayı dizinlemeden kapatır. "Allow", adından da anlaşılacağı gibi, sayfaların dizinlenmesine izin verir. Örneğin, normalde işlenmekten engellenen bir dizindeki bir alt dizin veya sayfayı taramaya izin verir.
Bu yönergeler şu formatta belirtilir:
yönerge: [path], burada [path] (sayfa veya bölüme giden yol) isteğe bağlıdır.
Bununla birlikte, yol belirtmezseniz robotlar Allow ve Disallow yönergelerini yok sayar. Bu durumda, tüm içeriği tarayabilirler.
Boş bir yönerge Disallow:, yönerge Allow: / ile eşdeğerdir, yani "hiçbir şeyi reddetme".
Sitemap yönergesinde bir hata örneği:
Sitemap:
Sitemap'e giden yol belirtilmemiş.
Doğru seçenek:
Sitemap: https://www.site.com/sitemap.xml
Kuraldan önce User-agent yönergesi yok
Kural her zaman User-agent yönergesinden sonra gelmelidir. İlk user agent adından önce bir kural yerleştirmek, hiçbir tarayıcının ona uymayacağı anlamına gelir.
Bir hata örneği:
Disallow: /category User-agent: Googlebot
Doğru seçenek:
User-agent: Googlebot Disallow: /category
"User-agent: *" formunun kullanımı
User-agent: * gördüğümüzde, bu, kuralın tüm arama robotları için ayarlandığı anlamına gelir.
Örneğin:
User-agent: * Disallow: /
Bu, tüm arama robotlarının tüm siteyi dizinlemesini yasaklar.
Bir robot için yalnızca bir User-agent yönergesi ve tüm robotlar için yalnızca bir User-agent: * yönergesi olmalıdır.
Aynı user agent için robots.txt dosyasında birkaç kez farklı kural listeleri belirtilirse, arama robotlarının hangi kuralları dikkate alacağını belirlemesi zor olur. Sonuç olarak, robot hangi kurala uyacağını bilemez.
Bir hata örneği:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Doğru seçenek:
User-agent: * Disallow: /category Disallow: /*.pdf.
Bilinmeyen yönerge
Arama motoru tarafından desteklenmeyen bir yönerge bulundu.
Bunun nedenleri aşağıdaki gibi olabilir:
- Var olmayan bir yönerge yazılmış;
- Sözdizimi hataları yapılmış, yasaklanmış semboller ve etiketler kullanılmış;
- Bu yönerge diğer arama motoru robotları tarafından kullanılabilir.
Bir hata örneği:
Disalow: /catalog
"Disalow" yönergesi mevcut değil. Kelimenin yazımında bir hata var.
Doğru seçenek:
Disallow: /catalog
Robots.txt dosyasındaki kural sayısı izin verilen maksimumu aşıyor
Arama robotları, robots.txt dosyasının boyutu 500 KB'yi aşmadığı sürece dosyayı doğru şekilde işler. Dosyadaki izin verilen kural sayısı 2048'dir. Bu sınırın üzerindeki içerik yok sayılır. Bunu aşmamak için, her sayfayı hariç tutmak yerine daha genel yönergeler kullanın.
Örneğin, PDF dosyalarının taranmasını engellemeniz gerekiyorsa, her dosyayı engellemeyin. Bunun yerine, .pdf içeren tüm URL'leri şu yönerge ile yasaklayın:
Disallow: /*.pdf
Kural izin verilen uzunluğu aşıyor
Kural 1024 karakterden fazla olmamalıdır.
Yanlış kural formatı
Robots.txt dosyanız UTF-8 kodlamalı düz metin olmalıdır. Arama motorları UTF-8 dışı karakterleri yok sayabilir. Bu durumda, robots.txt dosyasındaki kurallar çalışmaz.
Arama robotlarının robots.txt dosyasındaki talimatları doğru şekilde işlemesi için, tüm kurallar Robot Hariç Tutma Standardı'na (REP) göre yazılmalıdır, ki Google bunu destekler ve çoğu bilinen arama motoru bunu destekler.
Ulusal karakterlerin kullanımı
Robots.txt dosyasında ulusal karakterlerin kullanımı yasaktır. Standart onaylı alan adı sistemine göre, bir alan adı yalnızca sınırlı bir ASCII karakter kümesinden oluşabilir (Latin alfabesinin harfleri, 0-9 arası rakamlar ve kısa çizgi). Alan adında ASCII dışı karakterler (ulusal alfabeler dahil) varsa, geçerli bir karakter kümesine Punycode dönüştürülmelidir.
Bir hata örneği:
User-agent: Googlebot Sitemap: https: //bücher.tld/sitemap.xml
Doğru seçenek:
User-agent: Googlebot Sitemap: https://xn-bcher-kva.tld/sitemap.xml
Geçersiz bir karakter kullanılmış olabilir
Özel karakterler "*" ve "{{input}}quot;" kullanımı izin verilir. Yönergeleri beyan ederken adres kalıplarını belirtirler, böylece kullanıcının engellenecek uzun bir son URL listesi yazması gerekmez.
Örneğin:
Disallow: /*.php$
herhangi bir PHP dosyasının dizinlenmesini yasaklar.
- Yıldız "*" herhangi bir diziyi ve herhangi bir sayıda karakteri belirtir.
- Dolar işareti "{{input}}quot;" adresin sonunu belirtir ve "*" işaretinin etkisini sınırlandırır.
Örneğin, eğer /*.php .php. içeren tüm yollarla eşleşiyorsa, /*.php$ sadece .php ile biten yollarla eşleşir.
"{{input}}quot;" sembolü değerin ortasında yazılmış
"{{input}}quot;" işareti yalnızca bir kez ve yalnızca bir kuralın sonunda kullanılabilir. Önündeki karakterin son karakter olması gerektiğini belirtir.
Bir hata örneği:
Allow: /file$html
Doğru seçenek:
Allow: /file.html$
Kural "/" veya "*" ile başlamıyor
Bir kural yalnızca "/" ve "*" karakterleriyle başlayabilir.
Yol değeri, robots.txt dosyasının bulunduğu sitenin kök dizinine göre belirtilir ve kök dizini gösteren eğik çizgi "/" ile başlamalıdır.
Bir hata örneği:
Disallow: products
Doğru seçenek:
Disallow: /products
veya
Disallow: *products
dizinlemeden neyi hariç tutmak istediğinize bağlı olarak.
Yanlış sitemap URL formatı
Sitemap, arama motoru tarayıcıları içindir. Hangi sayfaların önce taranacağı ve hangi sıklıkta taranacağı konusunda öneriler içerirler. Bir sitemap'e sahip olmak, robotların ihtiyaç duydukları sayfaları daha hızlı dizinlemelerine yardımcı olur.
Sitemap URL'si şunları içermelidir:
- Tam adres
- Protokol belirtimi (HTTP: // veya HTTPS: //)
- Site adı
- Dosyaya giden yol
- Dosya adı
Bir hata örneği:
Sitemap: /sitemap.xml
Doğru seçenek:
Sitemap: https://www.site.ru/sitemap.xml
"Crawl-delay" yönergesinin yanlış formatı
Crawl-delay yönergesi, robot için bir sayfanın yüklenmesinin bitmesi ile bir sonraki sayfanın yüklenmesinin başlaması arasındaki minimum dönemi ayarlar.
Crawl-delay yönergesi, sunucunun ağır yük altında olduğu ve tarayıcının isteklerini işlemek için zamanı olmadığı durumlarda kullanılmalıdır. Ayarlanan aralık ne kadar büyük olursa, bir oturum sırasında o kadar az indirme yapılır.
Aralık belirtirken hem tamsayı değerler hem de kesirli değerler kullanılabilir. Ayırıcı olarak nokta kullanılır. Ölçü birimi saniyedir:
Hatalar şunları içerir:
- Birkaç Crawl-delay yönergesi;
- Crawl-delay yönergesinin yanlış formatı.
Bir hata örneği:
Crawl-delay: 0,5 second
Doğru seçenek:
Crawl-delay: 0.5
Not: Google, Crawl-delay yönergesini desteklemez. Bir Google botu için, Search Console webmaster panelinde isabet sıklığını ayarlayabilirsiniz. Ancak, Bing ve Yahoo botları Crawl-delay yönergesine uyar.
Satır BOM (Byte Order Mark) - U + FEFF karakterini içeriyor
BOM (Byte Order Mark - bayt sırası işaretçisi) U + FEFF formunda bir karakterdir ve metnin başında bulunur. Bu Unicode karakteri, bilgi okurken bayt sırasını belirlemek için kullanılır.
Standart programlar kullanarak dosya oluştururken ve düzenlerken, düzenleyiciler otomatik olarak BOM etiketiyle UTF-8 kodlaması atayabilir.
BOM görünür olmayan bir karakterdir. Grafiksel bir ifadesi yoktur, bu yüzden çoğu düzenleyici onu göstermez. Ancak kopyalandığında, bu sembol yeni bir belgeye aktarılabilir.
.html dosyalarında bayt sırası işaretçisi kullanırken, tasarım ayarları karışır, bloklar kayar ve okunamaz karakter setleri görünebilir, bu yüzden web komut dosyalarından ve CSS dosyalarından etiketi kaldırmak önerilir.
BOM etiketlerinden nasıl kurtulunur?
BOM'dan kurtulmak oldukça zordur. Bunu yapmanın kolay bir yolu, belgenin kodlamasını değiştirebilen bir düzenleyicide açmak ve BOM olmadan UTF-8 kodlamasıyla yeniden kaydetmektir.
Örneğin, Notepad ++ düzenleyicisini ücretsiz indirebilirsiniz. Ardından, BOM etiketi olan dosyayı açın ve "Kodlamalar" menü sekmesinde "UTF-8 (BOM olmadan)" öğesini seçin.
Robots.txt Validator hataları nasıl düzeltilir?
Bir robots.txt dosyası, arama motoru tarayıcılarına hangi sayfaları erişebileceğini ve erişemeyeceğini söyler. Tipik hatalar ve düzeltmeler şunları içerir:
- Robots.txt'nin kök dizinde olmaması. Bunu düzeltmek için dosyayı kök dizine taşımalısınız.
- Joker karakterlerin kötü kullanımı, örneğin * (yıldız) ve $ (dolar işareti). Yanlış yerleştirildiyse, bu karakteri bulup taşımalı veya kaldırmalısınız.
- Gelişim aşamasındaki sitelere erişim verme. Bir site yapım aşamasındayken, taranmasını durdurmak için disallow talimatını kullanabilirsiniz, ancak başlatıldıktan sonra bunlar kaldırılmalıdır.
- Şunu görürseniz:
User-Agent: * Disallow: /
Bu genellikle canlı sayfanın hala engellendiği anlamına gelir. - Robots.txt'nize bir sitemap URL'si eklememek. Bir sitemap URL'si, arama motoru botlarının sitenizin daha net bir görünümüne sahip olmasını sağlar.